Sử dụng dữ liệu không gian địa lý & học máy để dự đoán chất lượng nước ở Ethiopia

Mở rộng khả năng tiếp cận nước uống an toàn ở các nước thu nhập thấp và trung bình là ưu tiên phát triển con người quan trọng, được đặt ra ở cấp quốc gia và toàn cầu. Do đó, đảm bảo khả năng tiếp cận nước sạch và vệ sinh cho tất cả mọi người cũng là một trong những Mục tiêu phát triển bền vững.
Thông tin về chất lượng nước uống là chìa khóa để theo dõi tiến độ đạt được các mục tiêu quốc gia và toàn cầu. Vì vậy, điều quan trọng là phải đo chính xác chất lượng nước uống mà các hộ gia đình và cá nhân tiếp cận và xác định xem nước uống có bị ô nhiễm sinh học và hóa học hay không.
Hiện nay, ngày càng có nhiều quốc gia (trên 50 quốc gia) đã tích hợp kiểm tra chất lượng nước vào các cuộc điều tra hộ gia đình quốc gia để giám sát việc tiếp cận các dịch vụ nước uống được quản lý an toàn. Cách tiếp cận này cho phép thu thập thông tin đại diện cho các nhóm hộ gia đình và có khả năng phân chia kết quả theo các nhóm địa lý và kinh tế xã hội khác nhau.
Khả năng liên kết thông tin chất lượng nước với lượng thông tin phong phú được thu thập trong các cuộc điều tra hộ gia đình tạo điều kiện thuận lợi cho nghiên cứu cũng như xác định các biện pháp can thiệp hiệu quả nhằm cải thiện khả năng tiếp cận các dịch vụ nước uống được quản lý an toàn.
Tuy nhiên, việc tích hợp kiểm tra chất lượng nước trong điều tra hộ gia đình đòi hỏi phải có thêm nguồn tài chính và hỗ trợ kỹ thuật riêng biệt. Đồng thời có thể tăng gánh nặng cho các cơ quan thống kê, đặc biệt là trong bối cảnh nguồn lực hạn chế. Ví dụ, việc xét nghiệm vi khuẩn E. coli đòi hỏi phải có thiết bị, vật tư tiêu hao và đào tạo chuyên sâu cho nhân viên hiện trường về kỹ thuật vô trùng, ủ bệnh và diễn giải kết quả.
Lấp đầy những khoảng trống bằng tích hợp dữ liệu và học máy
Trong nghiên cứu “Giải quyết những thiếu sót trong dữ liệu về chất lượng nước uống thông qua tích hợp dữ liệu và học máy: bằng chứng từ Ethiopia” sự hợp tác giữa nhóm Nghiên cứu Đo lường mức sống của Ngân hàng Thế giới (LSMS) và Chương trình Giám sát Chung (JMP) của Tổ chức Y tế Thế giới và UNICE đã đề xuất một phương pháp nhằm lấp đầy những khoảng trống về dữ liệu về chất lượng nước uống.
Mặc dù việc thực hiện kiểm tra chất lượng nước trong mỗi cuộc điều tra hộ gia đình có thể không khả thi về mặt hậu cần và tài chính, nhưng dữ liệu thu được từ một cuộc điều tra gần đây có thể được tích hợp với dữ liệu không gian địa lý có sẵn công khai về lượng mưa, nhiệt độ, khoảng cách với chợ và đường gần nhất. Trong số những mô hình được sử dụng để thử nghiệm mô hình học máy nhằm tạo ra những hiểu biết đáng tin cậy về chất lượng nước uống trong những năm không có cuộc điều tra nào được tiến hành.
Quốc gia được chọn làm nghiên cứu điển hình cho nghiên cứu là Ethiopia. Năm 2016, khi dữ liệu mới nhất về chất lượng nước được thu thập trong khuôn khổ Điều tra kinh tế xã hội Ethiopia, khoảng 68% hộ gia đình được tiếp cận với nước uống từ các nguồn nước được cải thiện. Các nguồn nước như nguồn đường ống, giếng và suối đã được bảo vệ. Tuy nhiên, hơn một nửa số nguồn đó đã bị ô nhiễm (Hình 1).
Hình 1: Ô nhiễm E.Coli trong nước uống theo nguồn ở Ethiopia năm 2016
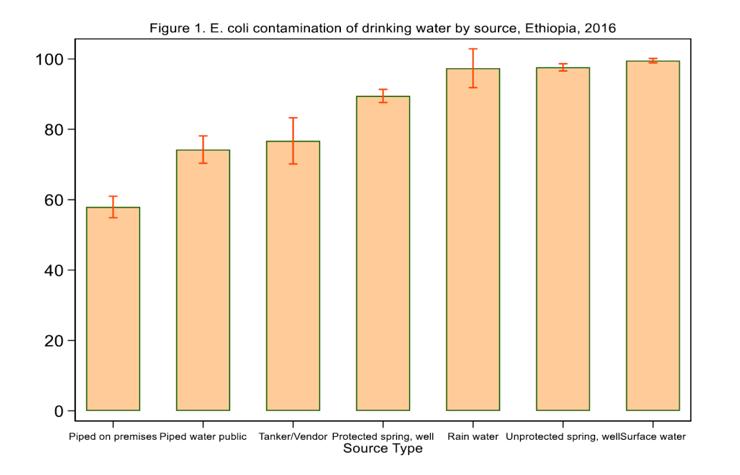
Sử dụng dữ liệu kiểm tra chất lượng nước từ điều tra kinh tế xã hội Ethiopia (ESS3) lần thứ ba vào năm 2016, nghiên cứu “Giải quyết những khoảng trống trong dữ liệu về chất lượng nước uống thông qua tích hợp dữ liệu và học máy: bằng chứng từ Ethiopia”, đã kiểm tra hiệu suất của một loạt thuật toán học máy thường được sử dụng để dự đoán ô nhiễm E. coli trong nguồn nước uống của hộ gia đình.
Nghiên cứu đã phát triển mô hình dự đoán ô nhiễm nguồn nước uống bằng cách tích hợp dữ liệu điều tra kinh tế xã hội với nguồn dữ liệu không gian địa lý trên cơ sở vị trí GPS của hộ gia đình. Nó so sánh một số thuật toán phân loại thường được sử dụng bao gồm GLM, GLMNET, KNN, Support Vector Machine và hai bộ phân loại dựa trên cây quyết định: Rừng ngẫu nhiên (RF) và XGBoost. RF hoạt động tốt nhất trên hầu hết các số liệu, trong đó XGBoost đứng thứ hai.
Nghiên cứu cũng kiểm tra hiệu suất của các nhóm biến dự đoán khác nhau, cụ thể là thuộc tính nhân khẩu học và kinh tế xã hội của hộ gia đình, đặc điểm dịch vụ nước và biến không gian địa lý, về hiệu suất của thuật toán và áp dụng mô hình dự đoán cho các làn sóng ESS khác, vào 2013/14 và 2018/19.
Nhìn chung, các dự đoán cho ESS3 (ESS 2015/16) tương đương với dữ liệu thực tế trong các kịch bản khác nhau. Nghiên cứu cho thấy rằng một mô hình có tất cả các biến dự đoán triển vọng được cho là có khả năng phân biệt đối xử mạnh (Diện tích dưới đường cong (AUC) 0,91; Khoảng tin cậy 95% (CI) 0,89, 0,94). Hiệu suất của mô hình kém khi loại nguồn nước là yếu tố dự đoán duy nhất (AUC 0,80; KTC 95% 0,77, 0,84).
Tuy nhiên, việc tăng cường các biến số nguồn nước bằng các yếu tố dự báo kinh tế xã hội cấp hộ gia đình được chọn, nhưng loại trừ các biến không gian địa lý, đã mang lại hiệu suất tương đương với mô hình đầy đủ (AUC 0,89; KTC 95% 0,86, 0,91).
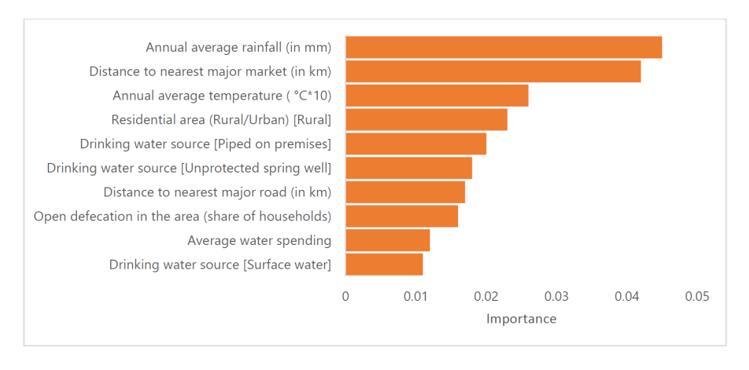
Mô hình chỉ có công cụ dự đoán không gian địa lý cũng đạt được hiệu suất tương đương với mô hình đầy đủ (AUC 0,91; KTC 95% 0,88, 0,93). Các biến không gian địa lý cũng là những yếu tố dự báo chính về mức độ ô nhiễm trong mô hình dự đoán đầy đủ (Hình 2).
Hình 2. Mức độ quan trọng của biến
Ba thông điệp chính rút ra từ nghiên cứu:
Phương pháp học máy có thể được sử dụng để phát triển mô hình và lấp đầy khoảng trống phát sinh do những thách thức trong việc thực hiện kiểm tra chất lượng nước.
Cuộc điều tra hộ gia đình với thử nghiệm nước và dữ liệu cơ bản về các đặc tính kinh tế xã hội, được tích hợp với các nguồn dữ liệu không gian địa lý, có thể được sử dụng để phát triển các mô hình dự đoán đáng tin cậy về chất lượng nước uống.
Với điều kiện, dữ liệu từ cuộc điều tra việc kiểm tra chất lượng nước tồn tại, các mô hình học máy dự đoán dựa vào các biến số không gian địa lý, đủ để hiểu các biến thể về nguy cơ ô nhiễm E. coli trong nguồn nước uống và tạo ra bản đồ rủi ro chất lượng nước.
Phạm Hạnh (dịch)
Nguồn: https://blogs.worldbank.org/opendata/using-geospatial-data-machine-learning-predict-water-quality-ethiopia